با استفاده از تجزیه و تحلیل لاگ های سرور و ترافیک زنده 137K دامنه با استفاده از Ahrefs Web Analytics و Bot Analytics، ما درخواست های به تمامی نام های شرکت های AI (3% از فایل هایی که نادیده گرفته نشدند) بررسی کردیم. این است که چه چیزهایی را پیدا کردیم.
- 28% از دامنه های 137K که از Ahrefs Web Analytics استفاده می کنند، یک فایل llms.txt منتشر می کنند.
- 97% از این فایل ها در ماه مه 2026 هیچ ترافیکی دریافت نکردند. هیچ چیز همچنین آنها را دریافت نکرده است.
- 96% از درخواست هایی که به فایل های llms.txt رسیده از بوت ها بود.
- 19.5% از فراخوانی ها از ابزار های AI نامی (از 3% فایل هایی که نادیده گرفته شدند) از طریق ابزار های کدزنی AI (GPTBot در رتبه اول و Claude-Code در رتبه دوم، جلوی هر بوت جستجو AI و کمکی).
- 12% از فراخوانی ها از صنعتی که خودش را مورد بررسی قرار داده: ابزار های GEO/AEO، ابزار های بررسی کننده llms.txt و پژوهشگران.
- صفر درخواستی از بوت های AI برای فایل های llms.txt که وجود ندارند آمد. هرگز به دنبال نمی روند.
- حسابرسی llms.txt Chrome Lighthouse تقریباً 1 در 1،000 فراخوانی می شود.
در اواخر ماه مه 2026، گوگل هر دو طرف از انجمن llms.txt را در زیر یک هفته گرفت.
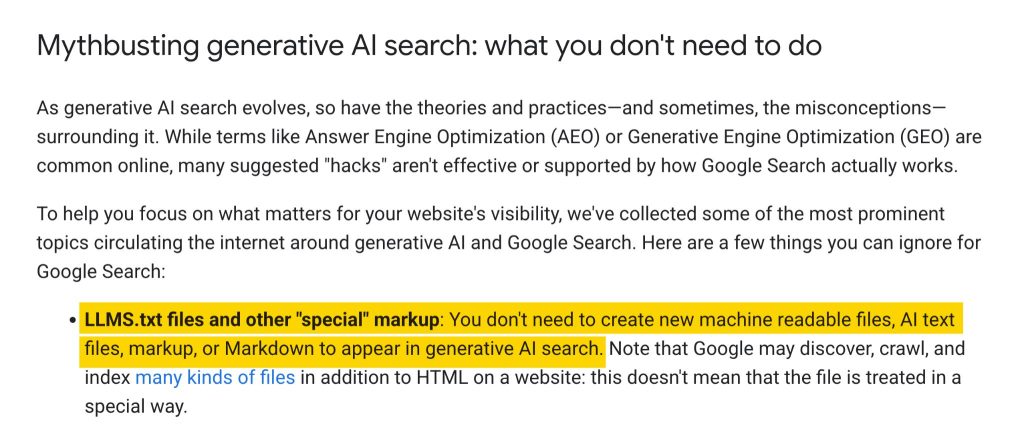
راهنمای جدید آن برای بهینه سازی برای ویژگی های AI تولید شده، به صاحبان سایت گفته است، در یک بخش با عنوان «تکذیب افسانه ای»، که فایل های خوانا برای ماشین مانند llms.txt برای ظاهر شدن در جستجوی هوش مصنوعی نیازی ندارند.
چند روز بعد، تیم Chrome یک بررسی llms.txt در داخل بررسی های مرورگر Agentic Browsing آزمایشی Lighthouse ارسال کرد، با توضیح آن که بدون فایل، عوامل ممکن است بیشتر از پیمایش یک سایت برای درک ساختار آن وقت بگذارند
هنگامی که Lily Ray از گوگل، John Mueller را در مورد این تناقض سوال کرد، او توضیح داد که llms.txt «برای جستجو انجام نشده است.» این یک «دسته عاریت موقت، شاید برای صرفه جویی در برخی از توکن ها» برای ابزار های کدزنی AI برای تجزیه و تحلیل اسناد توسعه دهنده است – چیزی که سایت های غیر توسعه دهنده باید نگران آن نباشند.
او همچنین اظهار داشت که صاحبان سایتی که لاگ های خود را بررسی می کنند، می فهمند که ترافیک بسیار کمی از طرف هوش مصنوعی وجود دارد.
این چیزی است که تصمیم گرفتیم تست کنیم.
قبل از ادامه، بیایید واضح کنیم که llms.txt در واقع چیست. Llms.txt یک فایل ایندکس تک، نوشته شده به زبان مارکداون، قرار داده شده در روت یک سایت است. این ایده از طرف Jeremy Howard، هم بنیان گذار Answer.AI و fast.ai، در سال 2024 پیشنهاد شد، این فایل خلاصه ای از این است که یک سایت چیست و به مهمترین محتوای خود لینک میکند. این ایده این است که LLM ها و هوش مصنوعی از این اطلاعات برای جهت یابی به خودشان استفاده کنند بدون این که همه چیز را پیمایش کنند. فریم بندی «قابلیت دیده شدن هوش مصنوعی» برروی llms.txt بعدا وصل شده است، که توسط صنعت سئو به تبعی از انتشار آن گسترده فرض شده است که پلتفرم های هوش مصنوعی پاداش فایل را پاداش می دهند. دو چیزی که معمولاً با آن همراه می شود و نیست.
- این تمرین فقط فایل ایندکس را اندازه گیری می کند، و فقط فایل ایندکس را.
- و با وجود نام فایل، این یک دستورالعمل robots.txt است: هیچ چیز را کنترل نمی کند و هیچ چیز را بلاک نمی کند.
این تحقیق نسبت به فایل ایندکس اندازه گیری می کند، و فقط فایل ایندکس.
تحقیق ما بر روی تمامی 137،210 دامنه در Ahrefs Web Analytics که ترافیک در ماه مه 2026 دریافت کرده اند تمرکز دارد.
هر ریشه دامنه را برای یک llms.txt بازگشت HTTP 200 بررسی کردیم، سپس از Bot Analytics Ahrefs استفاده کردیم تا هر درخواست به مسیر های llms.txt را در میان جمعیت، تقسیم شده توسط پاسخ HTTP (200 در مقابل 404) و طبقه بندی شده توسط کانال و عامل کاربری فردی، بررسی کنیم.
برای حذف 404 های نرم و فایل های شبح، همچنین تایید کردیم که هر فایل واقعی مارکداون بوده است، نه HTML، و عناوین و محتوا را برای سیگنال های خطا مانند «404» یا «صفحه یافت نشد» بررسی کردیم.
مهم است که توجه داشت:
- مشتریان Ahrefs Web Analytics نسبت به وب به طور کلی، فنی تر و از آگاهی بیشتری در زمینه سئو هستند، بنابراین به فیگر انتشار 28% رویکردند.
- ما به طور صریح بررسی نکردیم که آیا یک فایل به نحو مناسب خلاف مشخصه llms.txt بود یا نه.
28









محصولات مرتبط
-

پکیج مکمل، 30 بک لینک دائمی از سایتهای پیج رنک 8
290,000 تومان افزودن به سبد خرید -
تخفیف!

بک لینک مرحله2(2000سوشیال بوکمارک و پروفایلی)
قیمت اصلی 150,000 تومان بود.129,000 تومانقیمت فعلی 129,000 تومان است. افزودن به سبد خرید -

پکیج آلفا، 40 بک لینک دائمی از سایتهای پیج رنک 10
350,000 تومان افزودن به سبد خرید
